Nap: Network-Aware Data Partitions for Efficient Distributed Processing


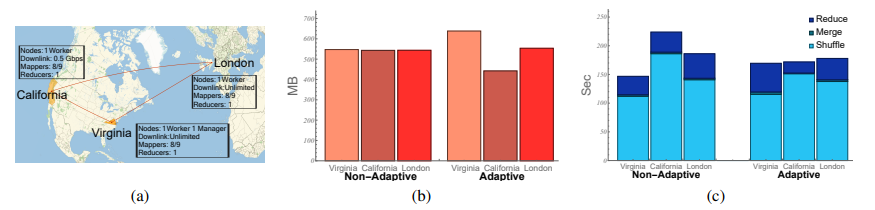
In order to support emerging data-intensive applications, many clever frameworks have been developed over the last years to efficiently and distributedly process big data sets, such as MapReduce. However, these frameworks are often optimized for relatively homogeneous environments, and accounting, e.g., for the varying connectivity of wide-area network infrastructure, may require complex placement algorithms. In this paper, we present Nap, which allows optimizing distributed data processing frameworks such as MapReduce for heterogeneous environments. Nap allows adapting resources dynamically, without requiring complex placement or migration algorithms, or modifications to the logic of the mappers and reducers. Rather, Nap simply changes the data partition, by spawning virtual nodes (e.g., reducers) depending on the demand. To this end, Nap leverages a connection to integer partition problems and employs Young lattices to guarantee minimal completion times (i.e., the makespan). In fact, Nap comes with provable performance guarantees and also supports applications that leverage redundancy to speed up executions further. In particular, to demonstrate our framework, as a case study, we show how to execute multiway joins across wide-area networks with limited bandwidth efficiently. Our experiments, based on a proof-of-concept prototype implementation, confirm the potential of Nap to reduce completion times.
 Top
Top
- Raz, Or
- Avin, Chen
- Schmid, Stefan
Top
Category |
Paper in Conference Proceedings or in Workshop Proceedings (Paper) |
Event Title |
18th IEEE International Symposium on Network Computing and Applications (NCA) |
Divisions |
Communication Technologies |
Subjects |
Informatik Allgemeines |
Event Location |
Cambridge, MA USA |
Event Type |
Conference |
Event Dates |
26-28 September 2019 |
Date |
2019 |
Export |
Top
