Data Locality and Replica Aware Virtual Cluster Embeddings


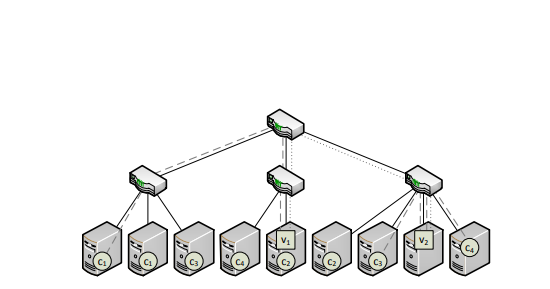
Virtualized datacenters offer great flexibilities in terms of resource allocation. In particular, by decoupling applications from the constraints of the underlying infrastructure, virtualization supports an optimized mapping of virtual machines as well as their interconnecting network (the so-called virtual cluster ) to their physical counterparts: a graph embedding problem. However, existing virtual cluster embedding algorithms often ignore a crucial dimension of the problem, namely data locality: the input to a cloud application such as MapReduce is typically stored in a distributed, and sometimes redundant, file system. Since moving data is costly, an embedding algorithm should be data locality aware, and allocate computational resources close to the data; in case of redundant storage, the algorithm should also optimize the replica selection. This paper initiates the algorithmic study of data locality aware virtual cluster embeddings on datacenter topologies. We show that despite the multiple degrees of freedom in terms of embedding, replica selection and assignment, many problems can be solved efficiently. We also highlight the limitations of such optimizations, by presenting several NP-hardness proofs; interestingly, our hardness results also hold in uncapacitated networks of small diameter.
 Top
Top
- Fuerst, Carlo
- Pacut, Maciej
- Schmid, Stefan
Top
Category |
Journal Paper |
Divisions |
Communication Technologies |
Subjects |
Informatik Allgemeines |
Journal or Publication Title |
Theoretical Computer Science |
ISSN |
0304-3975 |
Date |
2017 |
Export |
Top
